
Durante il keynote di oggi, un sorridente e “domestico” Jen-Hsun Huang ha presentato la nuova GPU Nvidia GA100, un mastodontico chip da 826 mm² con 6912 Unitá di Shading e ben 432 Tensor Cores prodotta da TSMC. A100 é un Acceleratore Grafico destinato ai datacenter evoluti dediti all’AI, all’ analisi dati e dall’ HPC, scalando l’elaborazione grafica fino a 7 istanze di calcolo indipendenti tramite la tecnologia MIG (Facile che in futuro saranno utilizzate anche per Geforce Now N.d.r.)
Quello che sorprende è che non si tratta nemmeno di una GPU nella sua configurazione massima, che conterebbe di ben 128 SM e 8192 Cuda Cores e 512 Tensor Cores.
A100 sará la scheda equipaggiata con il suddetto chip,dotato di tensor cores di terza generazione capaci di fornire prestazioni fino a 6 volte superiori nei calcoli TF32 (su matrice input/output FP32) della precedente Tesla V100. Grazie alla matematica TF32 gli sviluppatori non dovranno preoccuparsi di cambiare il linguaggio matematico utilizzato dato che i Tensor Core lavoreranno input e output in singola precisione.
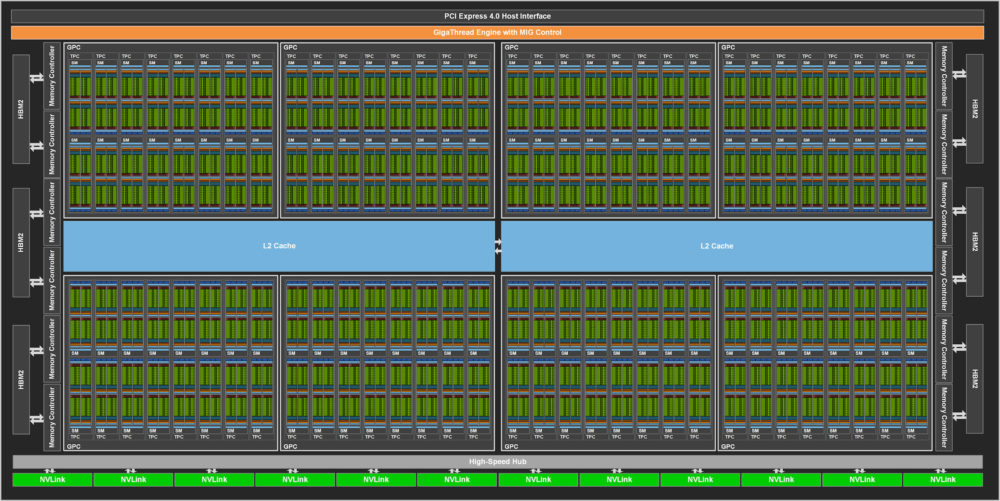
A100 dará inoltre un notevole boost prestazionale ai calcoli FP64 grazie alla tecnologia basata su Tensor Core denominata “Sparsity” capace di migliorare fino a duplicare i flussi di calcolo riordinando le matrici sparse per impacchettarle tramite TC. Tale potenza sarà estremamente utile nella ricerca scientifica e nelle simulazioni ad alta precisione di eventi fisici, e nell’allenamento dei Network AI.
Di seguito le specifiche
| GPU | GA100 |
| Memoria | 40Gb (HBM) |
| Shaders | 6912 |
| TMUs | 432 |
| ROPs | 160 |
| Clock Core | 1410Mhz |
| Clock Memorie | 1215Mhz |
| Processo Produttivo | 7nm (TSMC) |
Ben 8 Acceleratori A100 daranno vita al sistema Dgx A100, un concentrato di potenza per datacenter in grado di garantire prestazioni di ben 5PFLOPS (Crysis a 60fps in 8k per intenderci) al modico costo di 200.000 dollari.
Nel contempo, sono uscite indiscrezioni anche sulle componenti gaming di Ampere, che paiono essere dotate in versione Reference di ben 3 ventole e 2 connettori 8 pins, con supporto, ovviamente, a Pci-e 4.0.
Saranno divise in 3 classi, GA102 come top, dotata di 5376 cuda cores e con un IPC del 10% migliore in rapporto a Turing e frequenze nell’ordine dei 2.2 Ghz, 18 Gbps di banda ram con GDDR6 (863 GB/s) e circa 21 TFLOPs in FP32 con la possibile introduzione anche di Nvcache, simile a AMD HBCC di Vega.

A livello di performance si parla di un ventaglio dal 40% al 70% superiore rispetto a RTX 2080 ti, soprattutto in ambiti in cui entreranno in giochi effetti di Ray Tracing, senza contare la possibile introduzione di DSLL 3.0..
GA103, invece, potrebbe essere una classe intermedi inedita, che idealmente consentirebbe a 3080 di conquistare uno spazio proprio, slegandosi dalla classe 70, con frequenze fino a 2.5 Ghz.
Infine, GA104, la più piccola delle 3, utile a servire la fascia 3070-3060.
A livello di processo produttivo si parla di 7nm + per GA 102 e 103, mentre 7nm convenzionale per le classi inferiori: a settembre, comunque, Nvidia organizzerà un evento in prossimità del lancio dei nuovi modelli gaming.
Per ora, siamo felici che finalmente Ampere sia tra noi almeno a livello professionale e che tra non molto potremo metter mano su GPU Ampere votate al gioco.