
Processo Produttivo e Struttura SM di GA102
I nuovi chip Turing GA102 e GA104 sono basati su processo produttivo Custom a 8nm Samsung. Il passaggio dai 12Nm di TU102 agli 8Nm di GA102/104 dovrebbe garantire difatti un rapporto performance-per-watt migliorato del 90% rispetto alla serie precedente, comparabile di fatto a quanto visto in precedenza con A100, su nodo 7nm TSMC.
Uno dei nodi fondamentali su cui si sta dibattendo riguardo alle nuove RTX Ampere, é il mostruoso numero di Cuda cores dichiarato da Nvidia durante la presentazione del 1 Settembre scorso passando dai 4352 Cuda Cores di RTX 2080Ti agli 8704 di RTX 3080. Tali numeri, aiutati dalle poche informazioni reperibili al momento dell’ annuncio, hanno suscitato un misto tra euforia e scetticismo tra gli appassionati. Molti difatti si chiedevano -e si chiedono ancora- come sia possibile, nonostante il miglioramento del processo produttivo, raddoppiare il numero di Cuda Cores da una generazione all’ altra. Guardando al passato infatti, tali differenze si si son raggiunte ad ad esempio passando dal GM200 di 980ti, equipaggiato con 2816 cores, al TU102 di 2080Ti, con 4352 cores.
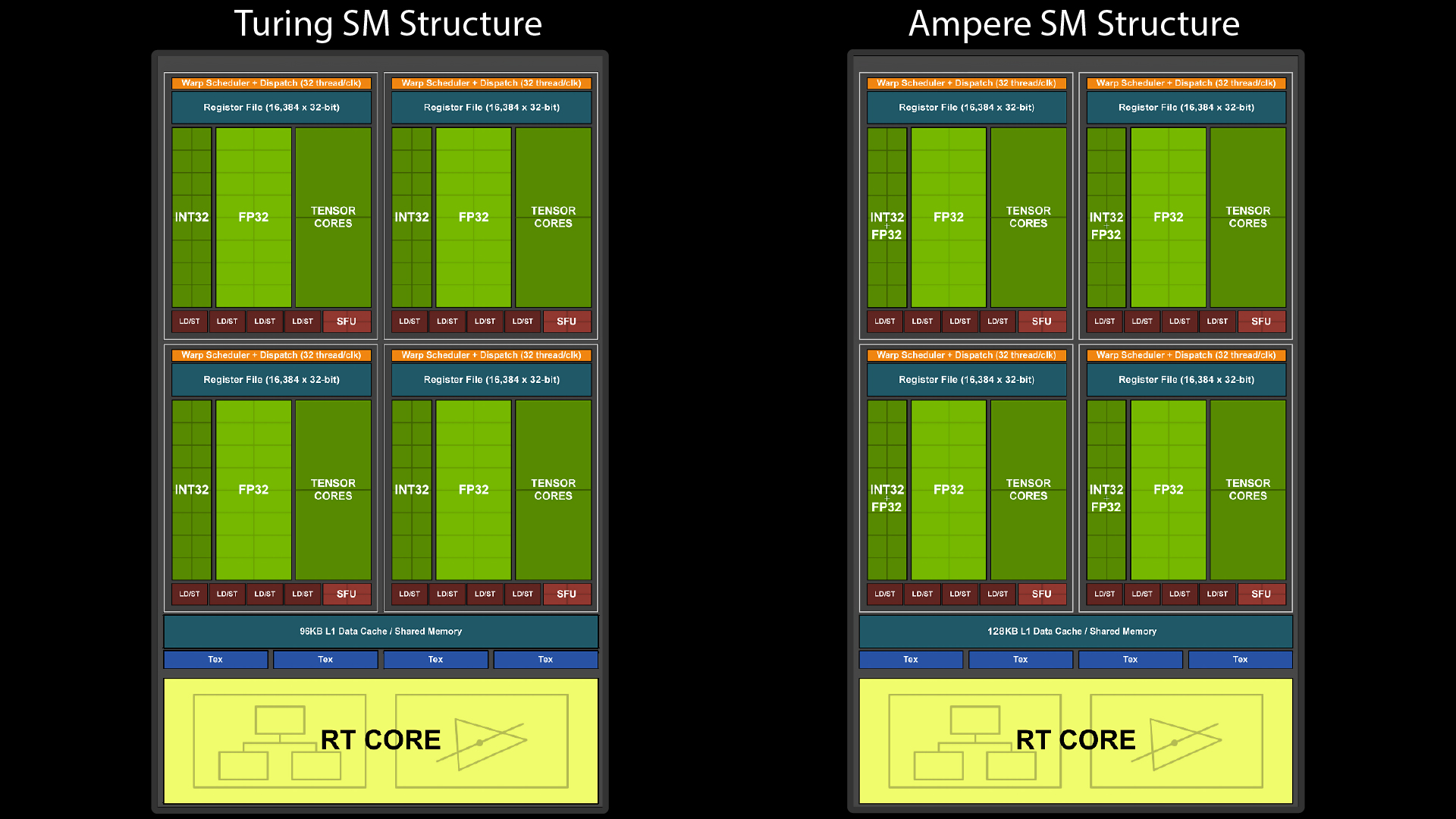
Il Segreto sta nell’innovativa struttura dei singoli Streaming Multiprocessor (SM) implementati in Ampere.
Ogni SM consiste nei Classici 4 Warp Scheduler + Dispatch SIMD. Invece che dividersi come in passato, in 16 Core FP32 e 16 core INT32, ogni sotto unitá può contare ora su 32 Shading Units (Cuda Cores) tutte in grado di effettuare calcoli FP32, 16 di esse, avranno peró il compito di eseguire simultaneamente calcoli INT32 (usati dagli shaders in minor quantitá rispetto ad FP32).
In poche parole, i Cuda cores sono effettivamente quelli dichiarati da Nvidia, ma la loro efficienza non sarà distribuita uniformemente all’ interno degli SM, Vedremo quindi con ogni probabilitá Cuda Cores “piú efficienti” di altri.
Se ci pensate, 3080 sulla carta ha piú del doppio dei TFlops di 2080ti, ma dalle prime prove “schede alla mano” le performance, sebbene più che soddisfacenti, son piú che lontane dall’ esser raddoppiate.
Quello che ancora non è chiaro è se l’ assegnazione dei calcoli FP32 avverrà in maniera ottimizzata per sfruttare i cuda più veloci per i calcoli più complessi, aumentando notevolmente le prestazioni. A tal proposito sembra che il ritardo delle recensioni di 3080 (previste per lunedì e uscite oggi) possa essere (anche) dovuto al rilascio posticipato di driver ottimizzati per la serie 3000.
Non vedo l’ora di averla tra le mie mani 🔥
ottima analisi tecnica….sintetica ed esaustiva….complimenti.
Per quel che riguarda la scheda nulla a dire è un mostro…credo che ad anno nuovo metterò mano all’intero pc