I cardini dell'offerta Radeon
Come abbiamo visto l’offerta Radeon passata, RDNA, pur supportando una notevole quantità di effetti sotto Fidelity FX, non è stata una soluzione DX12 ultimate pura, mancando dei quattro cardini che Microsoft ha stilato per poter apporre la sua certificazione.
RDNA2 non poteva, ovviamente, essere latente da questo punto di vista, considerando che la concorrente già nel 2018 rientrava dentro tali dettami, ha quindi ampliato il supporto adattando l’architettura dove serviva e mantenendo la già ottima base, vediamo punto per punto questi ulteriori spunti atti a ottimizzare l’esperienza:
- Mesh Shaders, una pipeline geometrica programmabile tramite compute dalle incredibili capacità, che se ben sfruttata, sarà in grado di traghettare nei calcoli Gpu alcune funzioni tradizionalmente elaborate dalla Cpu, con varie ottimizzazioni di Lod e HSR.
- Sampler Feedback, funzionalità atta a controllare lo streaming delle textures caricando solo quelle necessarie, ottenendo 2 enormi benefici: aumentarne il dettaglio e mitigare le necessità di archiviazione, una tecnica che può realmente modificare le performance effettive di caricamento, soprattutto in abbinamento con DirectStorage, oltre che consentire una maggiore fluidità nel passaggio tra zone che non hanno molti elementi a video a sezioni molto più elaborate (eliminando così lo stuttering o le problematiche di caricamento textures).
- Variable Rate Shading, in grado di identificare varie zone della scena e applicare un diverso livello di shading per ottimizzare la resa dell’immagine senza apparente degrado qualitativo.
Gli elementi, infatti, che necessitano di maggiore ombreggiatura saranno privilegiati, mentre tutto il resto avrà via via un minore dettaglio, consentendo di risparmiare potenza computazionale: RX 6800 supporta sia Tear 1 (per draw) e Tier 2 (per-draw e within-draw) che si differenziano per la minor flessibilità del primo approccio (che non utilizza screenspace image, ma solo draw calls) - Ray Tracing, non ha bisogno di presentazioni, essendo sulla bocca di tutti, ma l’implementazione di AMD è differente da quella Nvidia: l’hardware dedicato, RA (Ray Accelerators) calcola con funzioni fisse l’intersezione di 4 box per ciclo di clock o un triangolo, tutto il resto, invece, viene calcolato dalla pipeline della Gpu, compresa la fase di de-noising, affidata ai compute.
Nvidia, al contrario, ha sezioni dedicate della Gpu, RT cores, per il calcoli anche BVH, mentre utilizza l’IA dei Tensor Cores per fare de-noising.

Smart Access Memory
Un limite ereditato dal progresso tecnologico insito nei nostri Pc è il fardello di un passato a 32 bit: i sistemi operativi rilevavano un massimo di 4 Gb di ram, con possibilità di accesso a blocchi di 256 Mb per quanto riguarda la memoria video.
Siamo ormai ampiamente nell’epoca dei 64 bit, ma questo limite non è mai stato affrontato, anche perchè in gran parte dei casi non comportava un pregiudizio sulle performance: con l’avvento di Pci-e 4.0 e la nuova serie di chipset X570, Amd ha pensato una soluzione per consentire un accesso completo da parte della Cpu alla Ram installata sulla Gpu, disponendo, sola nel mercato (se si esclude Intel con Xe, ancora embrionali), di una piattaforma completa.
I registri BAR (Base Address Register) ridimensionabili (a seconda del quantitativo di Ram della Gpu) hanno bisogno di due prerogative: supporto a livello software nei drivers, supporto a livello di Firmware nelle mainboard, essendo comunque una caratteristica che rientra nella sfera PCI-SIG.
L’aumento di performance stimato dovrebbe toccare, in alcuni ambiti anche il 10%, assestandosi su una media ponderata di circa il 5-6%: al momento la tecnologia è limitata a Ryzen 5000 e chipset X570 e B550, ma non è escluso, anzi è probabile, che non sia un’impedimento Hardware, ma più una scelta commerciale, che sia da pregiudizio al supporto, con un aggiornamento del bios, a nuovi chipset e configurazioni.

Infinity Cache, l’arma in più.
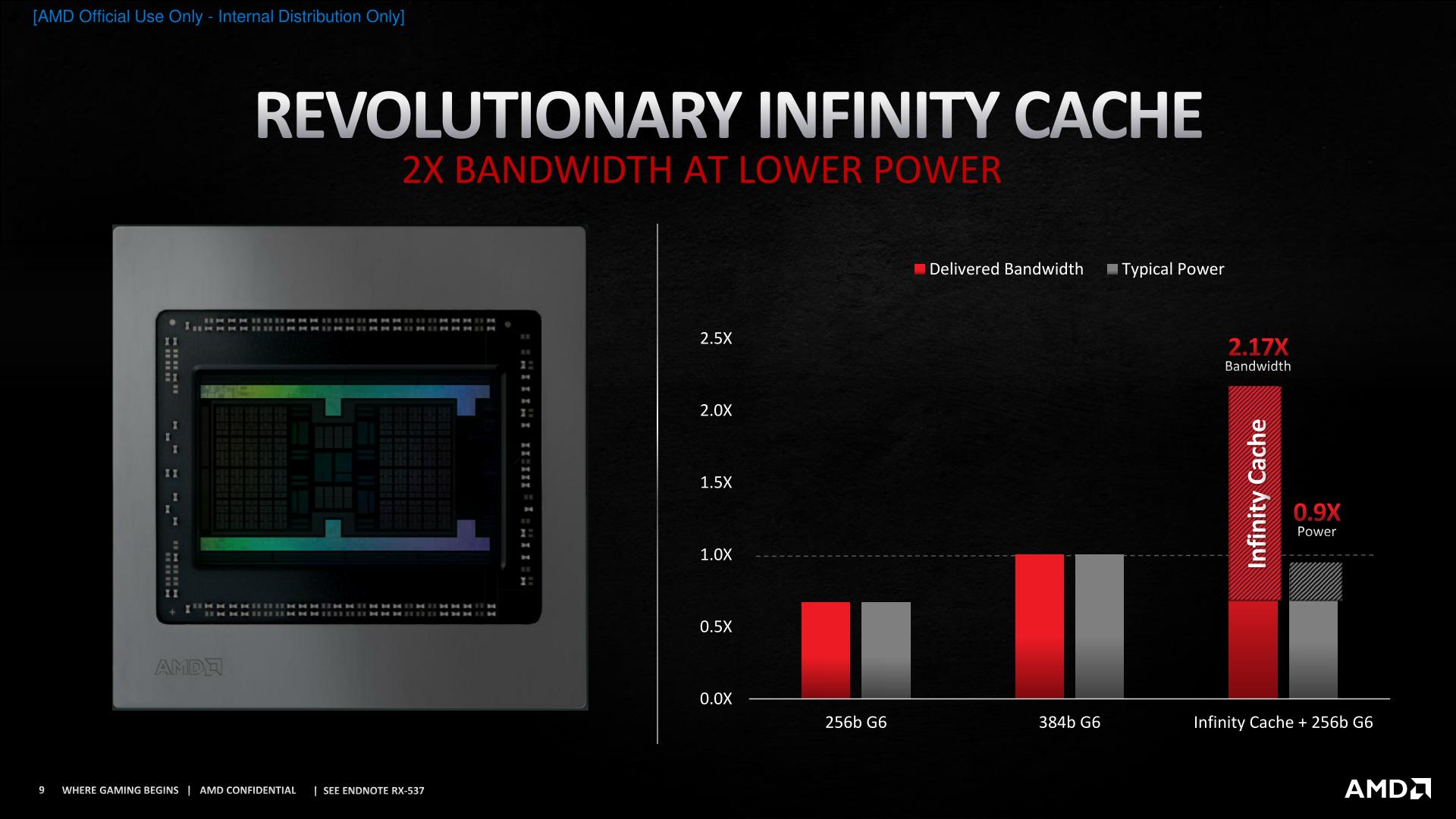
Uno degli aspetti più interessanti di RX 6800 e RX 6800 XT è sicuramente l’aggiunta, direttamente on chip, di ben 128 Mb di Cache, uno schema ripreso in maniera molto simile a quanto si è visto in ambito Cpu.
Tutto questo per quale motivo? Sostanzialmente perchè avere bus di interconnessione molto ampi, in particolare quelli da 512 bit, portano con loro delle problematiche progettuali e di ottimizzazione dell’architettura di difficile soluzione, oltre che una aumento di complessità e consumi.
De Facto, togliendo l’esperienza HBM che ha evidentemente perso la sua battaglia in ambito gaming, seppur portando indubbi benefici che non vogliamo negare, in una sola Gpu Amd si è visto un bus molto ampio impreziosito da uno schema ring-bus, ed è proprio, guarda caso, una soluzione che ebbe non pochi vincoli sia software che Hardware, pur portando sul piatto novità interessantissime come un chip in grado di calcolare, per la prima volta su Pc, le tesselation maps: parliamo, ovviamente, di AMD 2900 XT.
Con RDNA2 si è scelto l’approccio opposto: Bus di “soli” 256 Bit, GDDR6 a 16 Gbps e, appunto, infinity cache, in grado di comunicare con la Gpu in termini di velocità e latenza in maniera significativamente più veloce rispetto al reperimento del dato nella Vram, una sorta di buffer in grado di rendere le operazioni di lettura e scrittura molto, molto e ancora molto più efficienti.
Amd dichiara un miglioramento di performance nell’ordine del 117% in più rispetto a un tradizionale Bus a 256 bit e un a diminuzione di consumi nell’ordine del 10% rispetto a quello da 384 bit.
In ultimo non è da sottovalutare il suo apporto nel calcolo degli algoritmi per il supporto al Ray-tracing, che, come abbiamo già visto vengono elaborati, almeno in parte, tramite Compute, e i dati BVH passano necessariamente e in maniera ottimizzata dalla cache on chip.