
Aggiornamento del brevetto riguardo alle Gpu multi Chiplet da parte di AMD, registrato in data 1 aprile 2021 e disponibile QUI, in cui viene analizzato nel dettaglio l’active bridge, cioè la modalità di comunicazione tra i vari moduli GPU in modo da mantenere IPC e latenze a un livello consistente.
E’ interessante notare come gran parte del lavoro svolto con Infinity Cache e RDNA2 verrà ripreso e ampliato nei futuri modelli di GPU utilizzandolo come ponte in una sorta di grossa L3 condivisa tra i vari Chiplet, in questo esempio 3, che non sarà utilizzata solo per ottenere uno scaling migliore alle alte risoluzioni in rapporto al Bus, ma funzionerà, appunto, come interconnessione atta a sincronizzare le operazioni delle varie unità della GPU.
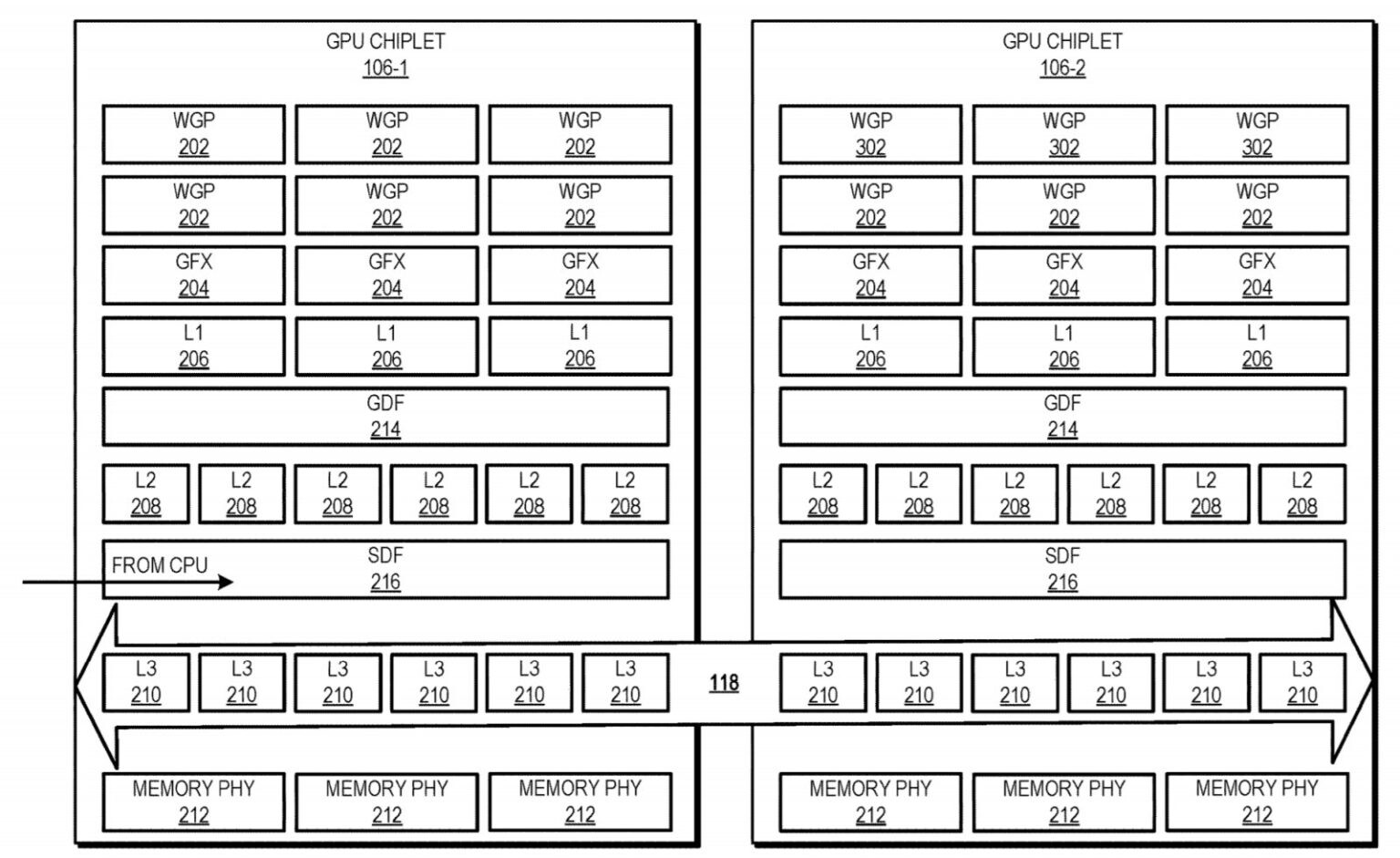
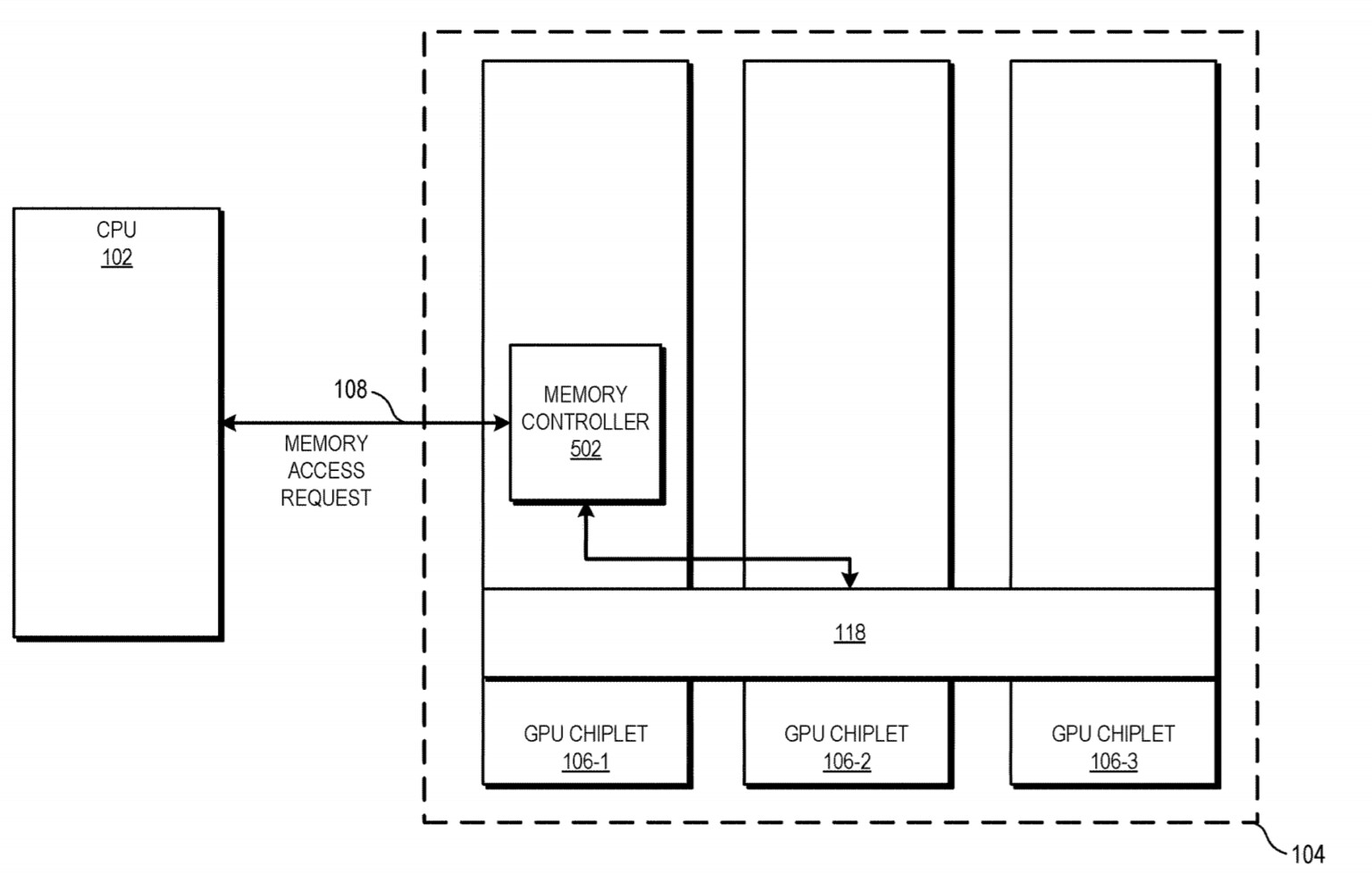
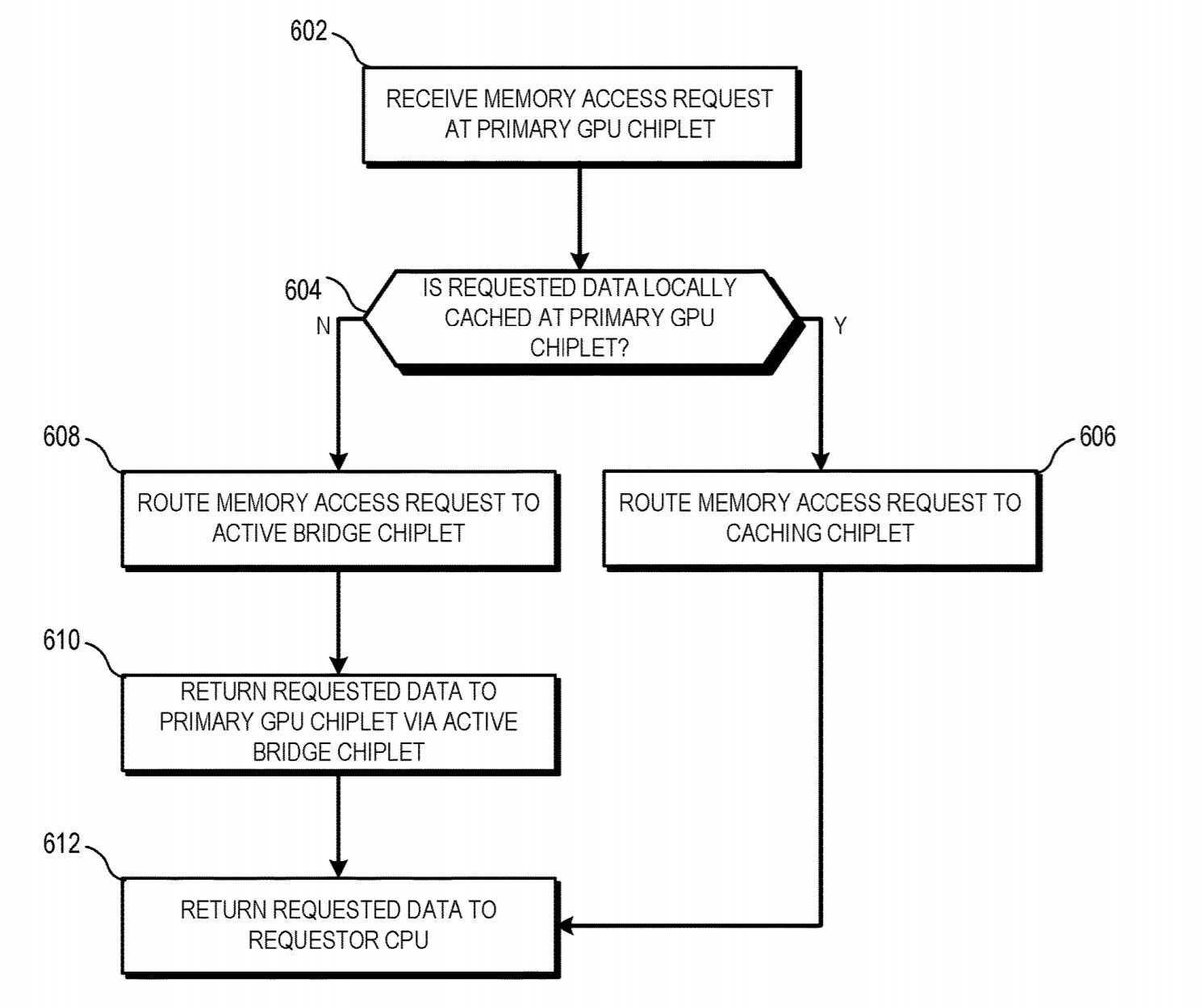
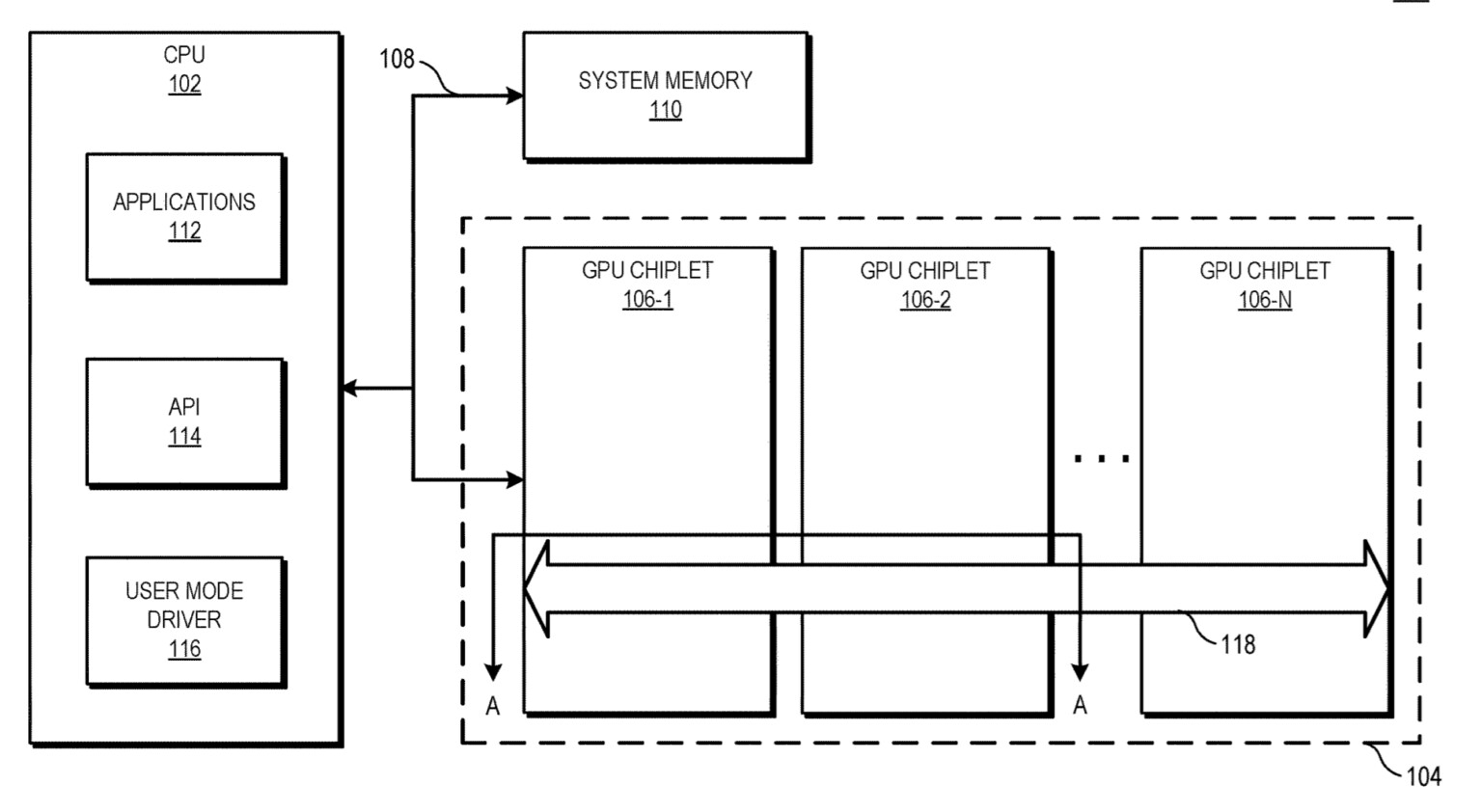
Riprendendo molto, quindi, dell’architettura della Cpu Zen 3, gli sviluppatori non si troveranno diverse sezioni di cache singolarmente riferite a ogni modulo, con i propri registri e una dipendenza dai drivers e programmazione svilente, ma una architettura snella che nella sua complessità manterrà un approccio unificato.
Ovviamente, come visto con la serie 5000 di Ryzen, il tutto aiuta a mantenere bassa la latenza interna: ogni chiplet Gpu avrà singolarmente un memory controller che attingerà, appunto, da una memoria L3 unificata.