
Architettura ADA LOVELACE
In questa versione saranno presenti un po’ meno di 4 GPC (Graphics Processing Cluster) che racchiudono le unità di calcolo raster, 12 SM e due blocchi da 8 ROPs ciascuno: in cima a ogni due unità SM troviamo una unità TPC (Texture processing Unit).
Base della pipeline di calcolo saranno gli SM, ognuno dotato di 128 Cuda Cores divisi in blocchi da 4, alcuni specializzati unicamente nei calcoli FP32 (la metà), altri potranno eseguire sia calcoli FP32 che INT32, un retaggio che ADA eredita da AMPERE (che serve ad avere un numero di unità di calcolo potenzialmente più elevato, ma effettivamente non utilizzabile mai al 100%, ad esempio, per operare in FP32)
Dentro ogni blocco di Cuda, inoltre, troviamo anche un RT core di terza generazione (per un totale di 12 per GPC) e 4 Tensor Cores di 4th generazione (per un totale di 48 per GPC), oltre a un taglio della memoria L2 condivisa che passa da 48 MB (di RTX 4070 ti) a 36 MB in questo caso.

Saranno 12 gli SM per GPC, 3 full con 1536 cuda cores e uno tagliato di 2 SM, che avrà quindi 1280 cuda cores, facendo quindi i conti della serva, 4608 cuda cores dai GPC completi e 1280 da quello incompleto che porta alle specifiche finali di 5888 cuda cores, 184 tensor cores (4×46), 64 ROPs e 46 RT cores.

Se a livello architetturale in termini quantitativi si può definire RTX 4070 una soluzione ragionevole, sono le tecnologie di supporto che la valorizzano maggiormente: con i nuovi core RT viene introdotta (un po’ come AMD ha fatto tagliando le iterazioni) una nuova tecnica chiamata DMM (Displaced Micro-Mesh), che sostanzialmente tende a semplificare i calcoli BVH (cioè il calcolo del percorso della luce) consentendo di sviluppare approssimazioni geometriche efficienti degli oggetti prima calcolati con un alto numero di poligoni, semplificando così i calcoli di interazione.
Vengono quindi applicate delle Mesh agli oggetti ottenendo molteplici benefici, un minor carico CPU frutto di modelli più semplici e minori richieste di Storage e Banda, Nvidia stima un rapporto tra 11 a 1 fino a 28 a 1 tra i vecchi modelli Turing e Ampere e Ada Lovelace grazie a DMM.
Abbinato a ciò abbiamo anche il SER (Shader Execution Reordering) in grado di far guadagnare un 20-30% di performance ottimizzando i calcoli inerenti all’applicazione del Ray Tracing con un pipeline più conforme alle specifiche di calcolo delle GPU Nvidia, riordinando dinamicamente le informazione che verranno processate.

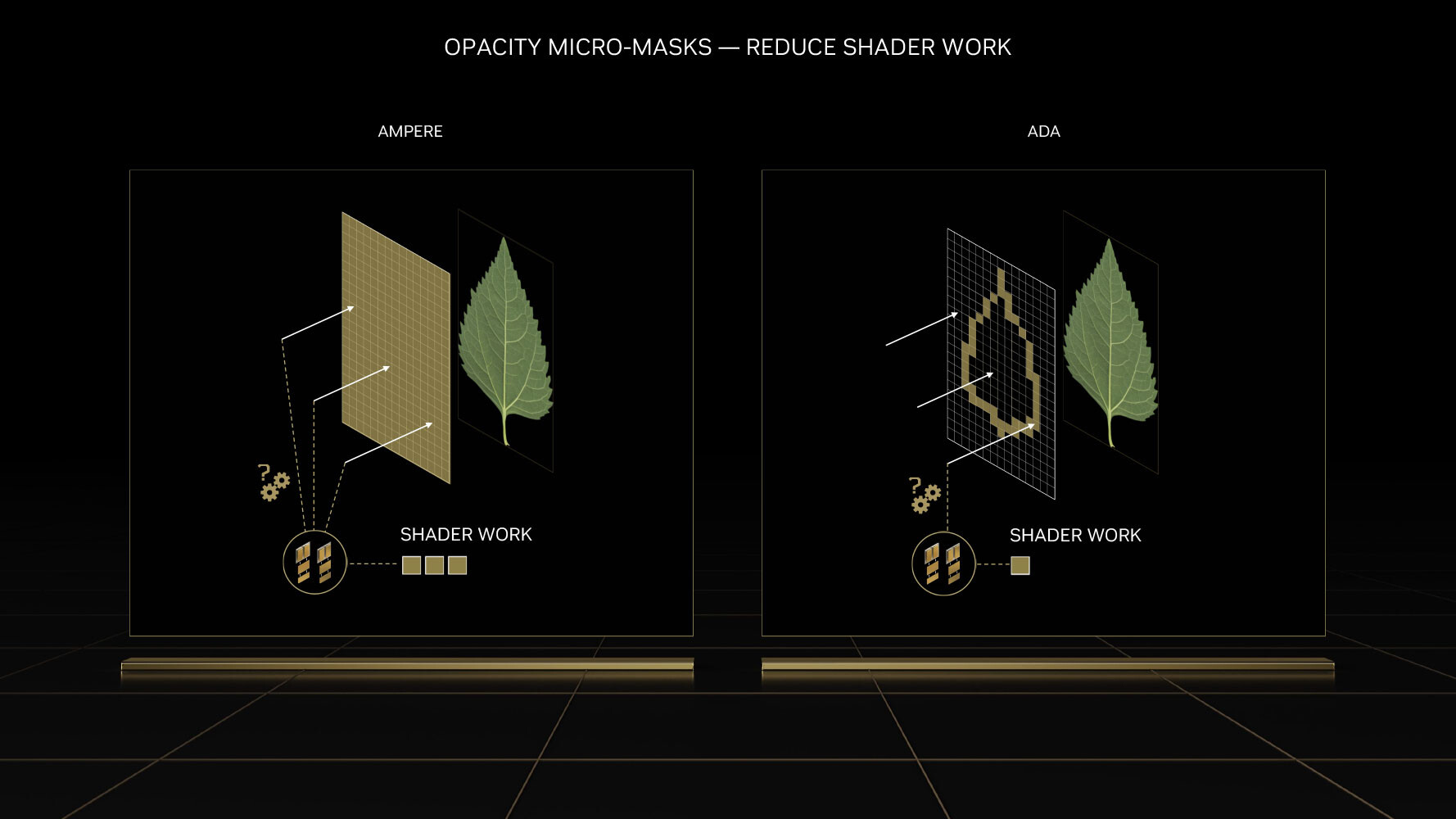
Ovviamente non si è tralasciato nemmeno l’ambito Raster, in cui la battaglia con AMD è più intensa, grazie a OMM (Opacity Micro Meshes), una tecnologia che intende ottimizzare tutti quelli effetti di trasparenza o oggetti in secondo piano che presentano valori alpha, sostituendo l’approccio di un unico rettangolo con applicato un layer di texture con la forma dell’oggetto, con un calcolo che consente in automatico di creare micro rettangoli seguendo le indicazioni della texture stessa.
Questa tecnica porta notevoli vantaggi anche nell’interazione con Ray Tracing, oltre che un aumento stimato delle performance del 10%.
Uno dei selling point, però, su cui Nvidia punta maggiormente è DLSS3, una tecnica di generazione di frame approssimati tramite AI che parte dal precedente DLSS2 2 (un upscaling tramite Tensor Cores), per estenderlo promettendo un frame rate doppio, estrapolando detta generazione dalla pipeline grafica (e quindi da colli di bottiglia CPU).
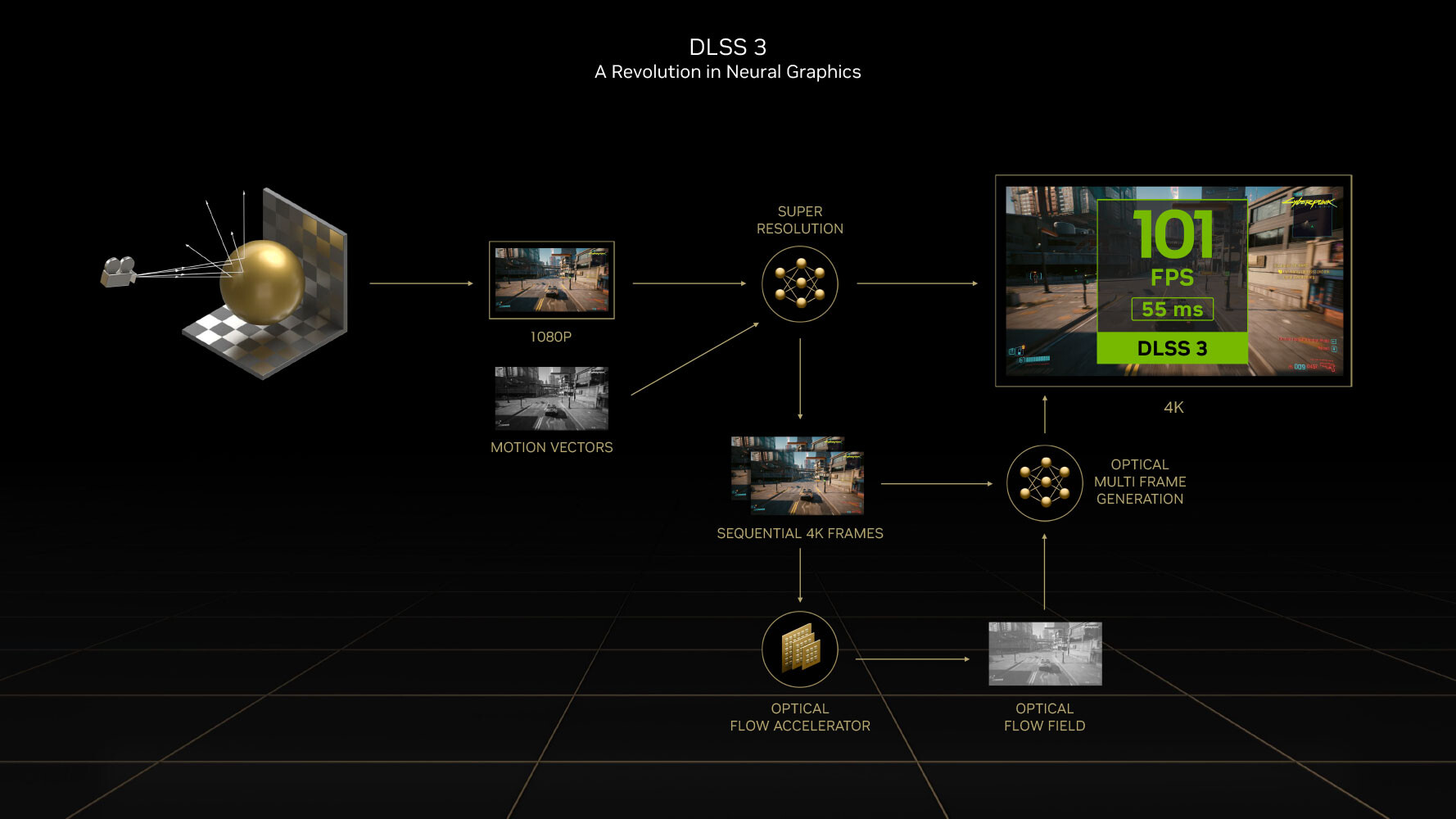
Attraverso OFA, infatti, Ada Lovelace sarà in grado di predire il frame successivo, che ovviamente dovrà essere leggermente diverso da quello precedente, grazie all’utilizzo in combinazione di Tensor Cores: questo approccio, però, rischia di generare artefatti e, ovviamente, latenze.
Sempre molto dettagliati e precisi nelle recensioni.
Credo proprio che andró a comprare la build suggerita da loro, ottimo prezzo e convenienza senza dover pensare ad installazione.
Non vedo l ora che arrivi a casa 🙂
Grazie, mi raccomando inserisci il codice VAULT che te lo scontano pure 😉
Trovo questa schiera video un buon prodotto, consumi contenuti, buone prestazioni anche se frutto di tanti render che non gradisco molto, però c’è da dire che con gpu fa il suo lavoro in 1440p.
Personalmente credo sia un po’ cara per quello che offre, secondo me sarebbe un best buy a 550€, considerando che adesso costa sui 715€ con 150€ in più si può andare su una 7900xt, che a livello di prestazioni offre di più.
Effettivamente è cara, non si può dire altrimenti, ma come prodotto è decisamente prestante e furbo.